



关注我们

出海网公众号

出海网小程序

出海网视频号

出海网社群


特点1: 大模型在训练时是将内容token化的,大模型所看到和理解的世界与你不一样
在理解模型行为之前,我们需要了解它是如何“学习”的。大型语言模型的预训练本质上是让模型建立文本片段之间的关联规律。为了实现这个目标,所有训练数据(包括书籍、网页、对话记录等)都会经过特殊处理:首先将文本切割成称为token的基本单元(类似文字的“碎片”),然后将这些token转化为数字编码。这个过程就像把现实世界的语言,翻译成只有模型能理解的“密码本”。

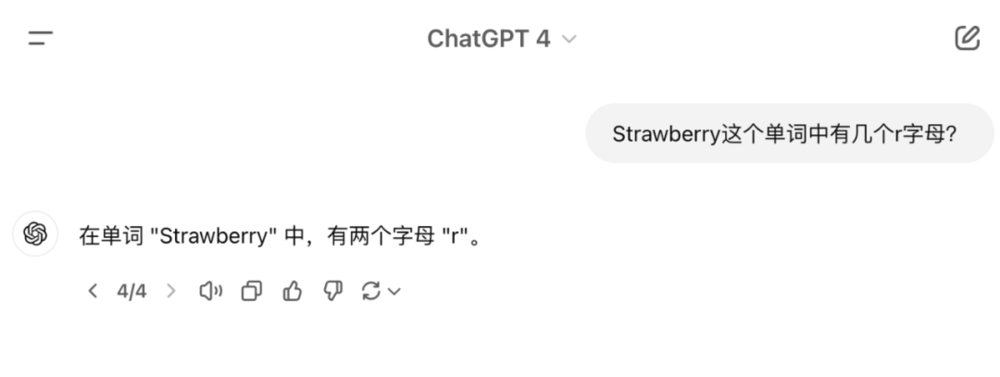
在推理模型出来之前,很多人非常喜欢用来考察大模型智商的一个问题是:Strawberry这个单词中有几个r字母?
此前像GPT-4、GPT-4o这类被认为很强大的大模型也没法把这个问题回答准确,这不是因为模型不够“聪明”,而是它在被训练时的特点导致了这一结果。
而所谓的token化就是大模型为了训练会将部分单词、中文字符进行拆分分解,比如在GPT3.5和GPT4的训练中,“词”这个字就被拆成了两个token,Strawberry则被拆成三个token,分别是“Str”“aw”“berry”。这种切割方式取决于训练时采用的tokenizer算法,也可能把生僻词拆解成无意义的片段。
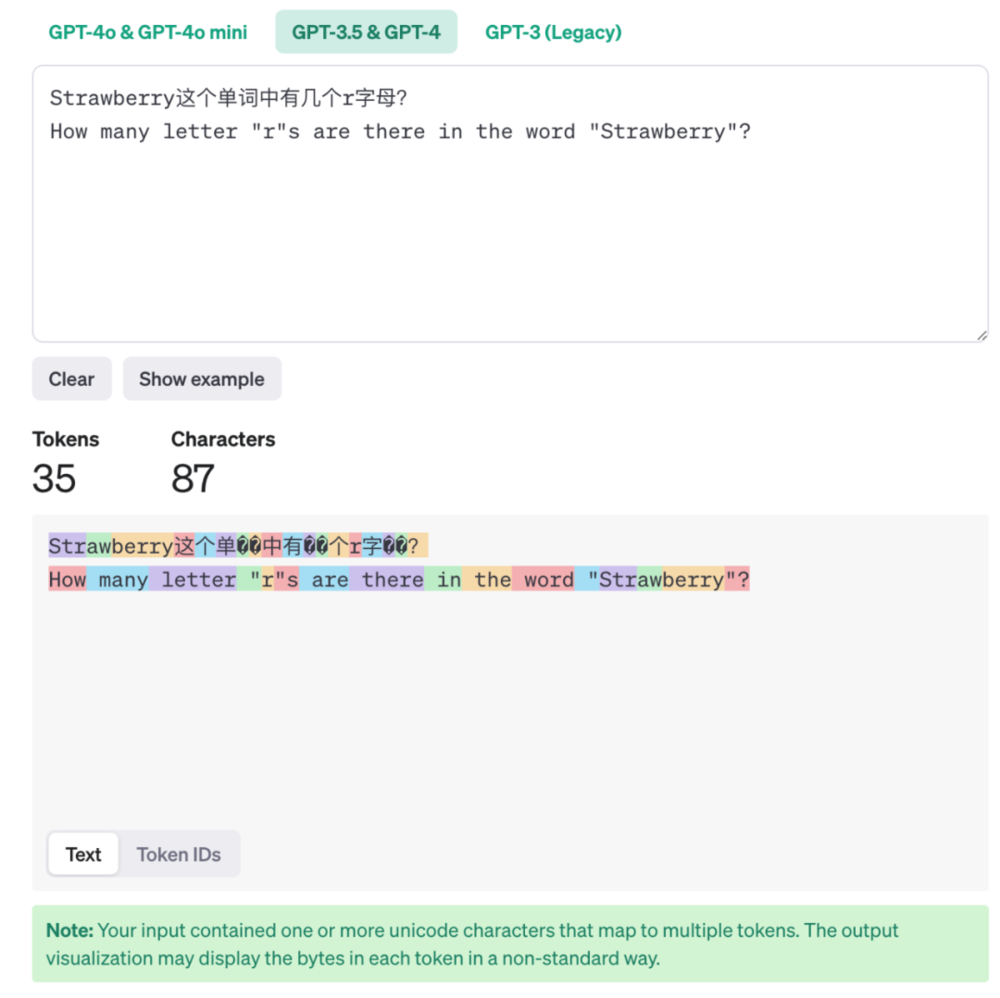
举这个例子是想告诉你,大模型所看到的世界和你所看到的不一样。当你在数字母时看到的是连续的字符流,而模型看到的却是经过编码的token序列。所以,类似于数单词中的字母数量,或者精确要求大模型为你输出特定字数的内容都是有些强模型所难的,他的机制决定了他不擅长处理这些任务。
当然,现在推理模型理论上可以完成我例子中的任务,但是你看看他推理的过程……是不是觉得还是有些费劲,有些于心不忍。

虽然DeepSeek R1在2025年1月才正式发布,但其基础模型的训练数据窗口期早在数月前就已关闭。这就像出版一本百科全书——从资料收集到最终付印需要完整的生产周期。具体来说存在三重时间壁垒:
(1)预训练阶段需要处理PB级原始数据;
(2)数据清洗需要经历去重、脱敏、质量验证等工序;
(3)后期还要进行监督微调、强化学习、基于人类反馈的强化学习(RLHF)等迭代优化。

这种知识滞后性会带来一系列的问题和幻觉,比如DeepSeek R1目前还认为GPT-4是世界上最强的模型,GPT-4o、Claude 3.5 Sonnet等2024年后发布的模型它是不知道的;它也无法告诉你2024巴黎奥运会赛事结果,无法告诉你2025年春晚或春节档的电影表现。
这些都是模型训练的特点导致的,很多人拿类似任务去问R1,发现R1答非所问,轻易得出R1模型太差的结论。事实上这就像要求2020年出版的《辞海》必须记载2021年的新词——本质是知识载体的物理特性使然。
要突破这种知识限制,也有方法:
激活联网搜索功能:给R1提供自主搜索查找信息的权力;
补充必要知识:你可以通过上传文档、在提示词中提供充足的信息之后,再让R1去为你执行具有更近时效性的任务。
特点3:大模型缺乏自我认知/自我意识
DeepSeek R1或者任何模型其实都缺乏“我是谁”的概念,如果他自发有了,那可能说明AGI临近,我们可能反而该警惕了。
很多模型都不知道自己叫xx模型,这是很正常的现象,除非大模型厂商在部署的时候在系统提示词中做了设定,或者预训练完成后用了特定的语料进行微调。

以及,因为这种自我认知的缺乏会带来两个问题:
(1)AI有时候会给出错误的自我认知,比如deepseek以及很多别的模型都可能认为自己是ChatGPT,因为ChatGPT发布后,很多人将自己与ChatGPT的对话内容发布在了网上。所以你在问一个模型“你是谁”“who are you”的时候,模型偶尔的幻觉是很常见的现象。
(2)你没法让DeepSeek R1来告诉你它自己有什么样的特点,使用它有哪些技巧等等。这也是我依然需要依靠大量自己的脑力算力去写作这篇文章的原因。
特点4:记忆有限
多数大模型都有上下文长度的限制,deepseek R1目前提供的上下文只有64k token长度(官方API文档的说明,实际聊天对话的长度待确认),对应到中文字符大概是3万~4万字,这带来的问题是,你没法一次投喂太长的文档给他,以及你没法与他进行太多轮次的对话。
当你发送的文档长度超过3万字时,你可以理解为他是通过RAG,也就是检索增强的方式去选取你文档中的部分内容作为记忆的一部分来展开与你的对话的,而不是全部内容。而当你与他对话的轮次过多时,他很可能会遗忘你们最初聊天的内容。
这部分的限制在你开展让AI写代码的任务时会感受尤其明显。
特点5:输出长度有限
相比上下文对话的输入长度,大模型的输出长度则会更短得多,多数大模型会将输出长度控制在4k或者8k,也就是单次对话最多给你2千~4千中文字符。
所以,你没法复制一篇万字长文让DeepSeek一次性完成翻译,也不能让DeepSeek一次性帮你写一篇5000字以上的文章,这些都是模型输出长度限制导致,你需要理解这个问题的存在。
如果要解决这个问题的话,翻译类的任务你可以通过多次复制,或者自己写代码去调用API多次执行任务完成一篇长文甚至一本书的翻译。而长文写作类的任务,比较妥当的做法是先让R1梳理框架列出提纲目录,再根据目录一次次分别生成不同阶段的内容。

